Dicas | Ferramentas | Notícias | Tutoriais
Como reduzir consumo de CPU em queries Oracle na prática?
Recentemente analisei um caso no Oracle Database onde o uso da CPU estava muito alto, entao, me perguntei — “Como reduzir o consumo de CPU na query?”
Muita gente analisa performance SQL olhando apenas o custo do plano de execução..
Fiz uma simples alteração no WHERE reduziu drasticamente o uso de CPU — mesmo com o custo do plano mudando quase nada.
E esse tipo de situação ensina MUITO sobre:
- seletividade
- índices
- FULL SCAN
- INDEX SCAN
- cardinalidade
- comportamento do otimizador Oracle
📌 O cenário
A query original era esta:
SELECT DISTINCT (CODESPECIE),
DESCRICAO
FROM CADESPECIE
WHERE CODESPECIE IN (
'CHQPRE','CHEQUE','CARTAO','TICKET')
);📌 O que foi alterado
Foi adicionado apenas um filtro extra:
AND CODFILIAL = 1Ficando assim:
SELECT DISTINCT (CODESPECIE),
DESCRICAO
FROM CADESPECIE
WHERE CODESPECIE IN (
'CHQPRE','CHEQUE','CARTAO','TICKET'
)
AND CODFILIAL = 1;Uma mudança simples.
Mas o impacto foi enorme.
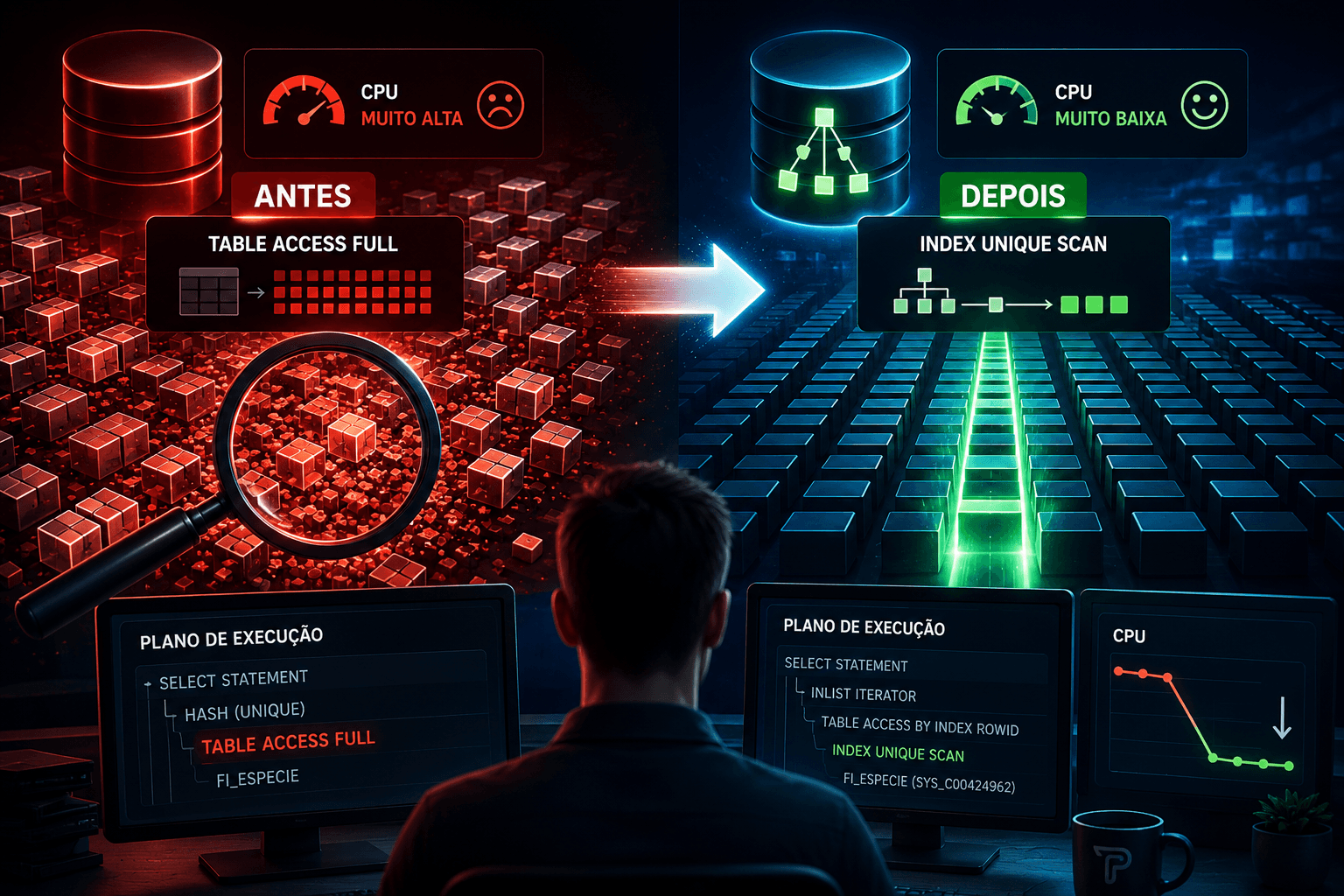
🔍 Plano de execução antes
O Oracle estava fazendo:
TABLE ACCESS (STORAGE FULL)Ou seja:
- leitura completa da tabela
- varredura de muitos blocos
- aplicação de filtros depois
- maior consumo de CPU
Além disso, o plano também mostrava:
HASH (UNIQUE)O que significa mais processamento para eliminar duplicidades do DISTINCT.
🔥 O ponto mais importante
Mesmo com filtro em coluna indexada, o Oracle decidiu:
“Vale mais a pena ler a tabela inteira.”
Isso acontece mais do que muita gente imagina.
E normalmente ocorre por:
- baixa seletividade
- estatísticas
- cardinalidade estimada
- custo estimado do índice
- quantidade de linhas retornadas
📌 O plano depois da alteração
Após adicionar:
AND CODFILIAL = 1O plano mudou para:
INDEX (UNIQUE SCAN)
TABLE ACCESS (BY INDEX ROWID)E aqui aconteceu a verdadeira mágica da performance.
🚀 Por que a CPU caiu tanto?
Antes
O Oracle fazia algo parecido com:
Lê a tabela inteira
→ depois filtra os registros
→ depois aplica DISTINCTDepois
Agora o Oracle consegue:
Ir direto no índice
→ encontrar poucos registros
→ acessar apenas linhas necessáriasResultado:
✅ menos leitura lógica
✅ menos leitura física
✅ menos blocos processados
✅ menos CPU
✅ menos memória
✅ menos trabalho geral do banco
📌 Mas o custo quase não mudou…
E aqui está a parte mais interessante.
Antes
Custo: 4Depois
Custo: 3Ou seja:
- praticamente igual
- mas a performance real mudou muito
🧠 O erro que muita gente comete
Muitos profissionais olham apenas isso:
COSTE assumem:
“Se o custo não mudou, então não houve ganho relevante.”
Mas no Oracle isso nem sempre é verdade.
O custo é apenas:
- uma estimativa do otimizador
- baseada em estatísticas
- cálculos internos
- previsões de acesso
Ele NÃO representa diretamente:
- CPU real
- tempo real
- I/O real
- concorrência
- impacto no ambiente
🔍 O verdadeiro indicador importante
O que realmente mudou foi:
Antes
TABLE ACCESS FULLDepois
INDEX UNIQUE SCANEssa troca costuma gerar ganhos enormes.
Porque o banco deixa de:
- procurar dados “no escuro”
- ler grandes volumes
- processar blocos desnecessários
E passa a:
- acessar exatamente o que precisa
📌 O detalhe da cardinalidade
Outro ponto interessante:
Antes
Cardinalidade: 44Depois
Cardinalidade: 13Isso mostra que o novo filtro aumentou a seletividade da consulta.
E quanto mais seletivo o filtro:
- maior a chance do índice valer a pena
- menor o custo operacional real
💡 Analogia prática
Imagine procurar uma pessoa em um estádio.
FULL SCAN
Você olha cadeira por cadeira.
INDEX SCAN
Você recebe:
- setor
- fila
- cadeira exata
A diferença de esforço é absurda.
Mesmo que no “papel” a estimativa pareça parecida.
🚨 Lição importante para tuning SQL
Nunca analise apenas:
- COST
- tempo isolado
- índice existente
Analise também:
- tipo de acesso
- cardinalidade
- seletividade
- quantidade de linhas
- leitura lógica
- leitura física
- estratégia do plano
Porque pequenas mudanças no WHERE podem alterar completamente o comportamento do Oracle.
📌 Resumo rápido
Antes
❌ FULL TABLE SCAN
❌ Mais CPU
❌ Mais leitura
❌ HASH UNIQUE pesado
Depois
✅ INDEX UNIQUE SCAN
✅ Menos CPU
✅ Menos leitura
✅ Melhor seletividade
✅ Acesso direcionado
🚀 Conclusão
Esse caso mostra algo que muitos profissionais só descobrem na prática:
Performance não é apenas sobre custo do plano.
Às vezes:
- uma pequena mudança no filtro
- altera completamente a estratégia do Oracle
- e gera ganhos enormes de CPU e tempo
E isso reforça uma das habilidades mais importantes em SQL tuning:
✅ entender o comportamento do plano
e não apenas olhar números isolados.
Tenho outro post que vai te ajudar tambem e melhorar a performance, acesse aqui
🔗Referência